

An AI agent that can call tools, move money, and run code is only as safe as the limits you put around it. That is what AI agent guardrails are: programmatic checks that sit between the user, the model, and the tools, vetting every request and response before anything executes. The need is now mainstream — Gartner projects that 40% of enterprise applications will embed task-specific AI agents by the end of 2026, up from under 5% in 2025, while only 20% of organizations have a mature AI governance model. The cleanest way to close that gap is to enforce guardrails at one control point in front of every model and tool call — exactly what an AI gateway like OrcaRouter is built to do, with content-policy guardrails and risk scoring applied before a request is ever billed.
Quick take: Guardrails come in four flavors — input, output/content, behavioral/action, and topical. The safest setups don’t trust the agent; they layer all four at a single enforcement point, add risk scoring, and block or hold anything that looks unsafe before it runs or costs money. Treat the model as untrusted by default.

The four guardrail types and what each one checks. Combine them — no single layer is enough.
What AI agent guardrails actually are
Guardrails are not the model’s training or its system prompt — those can be talked around. They are checks layered around the model that enforce policy regardless of what the agent decides to do. NVIDIA’s open-source NeMo Guardrails toolkit defines five rail types — input, dialog, retrieval, execution, and output; most teams collapse these into four practical categories.
The four types of guardrails
| Type | What it checks | When it fires |
| Input guardrails | Prompt injection, jailbreaks, PII, off-policy requests | Before the model sees the prompt |
| Output / content guardrails | Toxicity, policy violations, leaked PII, hallucinations, schema | Before the user sees the response |
| Behavioral / action guardrails | Which tools the agent may call, with what scope and limits | Before a tool or action executes |
| Topical limits | Whether the request is in the agent’s domain at all | At input, before processing |
1. Input guardrails
These intercept and evaluate everything entering the system before it reaches the model, making them the primary defense against prompt injection. They scan user text, tool outputs, and retrieved documents for injection patterns and strip PII or secrets. Classifier models help here: Meta’s Llama Guard returns a safe/unsafe label plus category codes at roughly one-third the false-positive rate of GPT-4 on its benchmark, and lightweight prompt-guard models flag jailbreak attempts.
2. Output / content guardrails
Output rails scan responses for hallucinations, toxic content, policy violations, and sensitive data before the user sees them. This is also where structure gets enforced: Guardrails AI uses a validator architecture with a 50+ validator hub at ~50–200ms per validation to guarantee an LLM’s output matches a required schema and policy.
3. Behavioral / action guardrails
The category that matters most for agents. Execution guardrails control agent actions, tool use, retrieval access, and runtime decisions, with rate limiting and anomaly detection at this layer. In practice that means least-privilege tool scoping and approval gates on high-impact actions — payments, deletes, external sends. An over-permissioned agent is one clever prompt away from misusing access it never needed.
4. Topical limits
Topical rails keep the agent inside its job. Defining on-topic versus off-topic means scoping the application exactly — a banking agent answers account and loan questions but refuses cooking recipes, sports scores, or political opinions. This shrinks the attack surface and stops the agent from being repurposed.
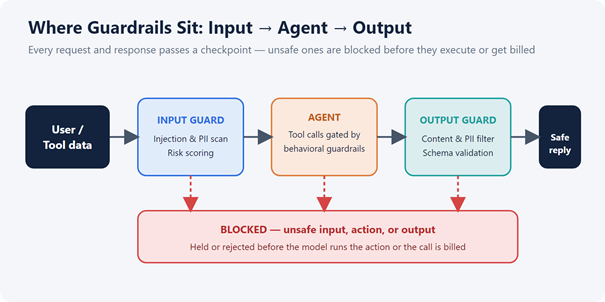
Each checkpoint can block a request before the model acts or the call is billed.
Where guardrails run: in-app vs. at a gateway
Guardrails can live inside each application or in front of all of them.
- In-app (application layer). Libraries like NeMo Guardrails run inside your code; NeMo operates as a library rather than a gateway, so rail logic is owned per service. Maximum control, but you re-implement and maintain rails for every agent.
- At a gateway (infrastructure layer). When guardrails run at the gateway level, every API request is automatically protected regardless of which client or SDK you use. You define policy once and it applies fleet-wide. Most enterprises with many applications pair a library with a gateway to keep enforcement consistent.
An AI gateway is the natural home for input filtering, PII redaction, content guardrails, and role-based access — one enforcement point across every provider, instead of bolting controls onto each agent.
Guardrails + risk scoring = stopping unsafe actions early
The newest move pairs guardrails with continuous risk scoring. An AI agent gateway intercepts every tool invocation, evaluates it against policy, scores the risk, and approves or blocks execution before it happens — the core idea behind Gartner’s AI TRiSM framework, which risk-scores models, applications, and agents and inspects runtime behavior to detect policy violations. Scoring at the gateway also catches cost abuse: a flagged request blocked before it reaches the model never gets billed — which matters when Gartner expects over 40% of agentic AI projects to be canceled by end of 2027, partly over escalating costs and inadequate risk controls.
The bottom line
AI agent guardrails in 2026 are a governance discipline, not a feature you toggle on the model. Layer the four types — input, output, behavioral, and topical — assume the agent can be manipulated, and gate every high-impact action. Put those controls at a gateway with risk scoring and you get them once, everywhere, and you stop unsafe requests before they execute or cost you money. With regulators setting hard 2026 deadlines such as the EU AI Act’s high-risk obligations on 2 August 2026, that shift from nice-to-have to non-negotiable is already here.
Frequently asked questions
What are AI agent guardrails? Programmatic checks layered around an AI agent that vet inputs, outputs, and actions against policy — constraining what the agent can do, not just what the model was trained to say.
What are the main types of guardrails? Four practical categories: input (screen prompts), output/content (validate responses), behavioral/action (scope tool use), and topical (keep the agent on-domain). NeMo Guardrails splits these into five rail types.
Which guardrail frameworks should I look at? Common stacks combine Llama Guard as a fast classifier, NeMo Guardrails for dialog control, and Guardrails AI for output enforcement — three abstractions for three jobs.
Should guardrails run in the app or at a gateway? A gateway protects every request regardless of client or SDK and is easier to govern across many agents; in-app libraries give finer control. Large fleets usually use both.
How do guardrails stop unsafe actions before they happen? A gateway scores each action’s risk and blocks or holds it before execution — and before the request is billed.