

Perplexity is a cornerstone metric in the field of natural language processing (NLP) and machine learning. It is widely used to evaluate the performance of probabilistic models, particularly language models, by measuring their ability to predict data accurately.
While the concept may seem abstract at first, perplexity plays a crucial role in understanding how well a model can handle the inherent complexities of language.
This article delves into the concept of perplexity, its mathematical foundations, practical applications, and limitations, offering a comprehensive view of why it is so essential in NLP.
What is Perplexity?

Perplexity, in its simplest form, measures how well a probabilistic model predicts a set of events, such as words in a sentence. It quantifies the degree of “surprise” the model experiences when encountering actual data. A model that assigns high probabilities to the correct predictions will have low perplexity, while one that guesses or assigns low probabilities to the correct predictions will exhibit high perplexity.
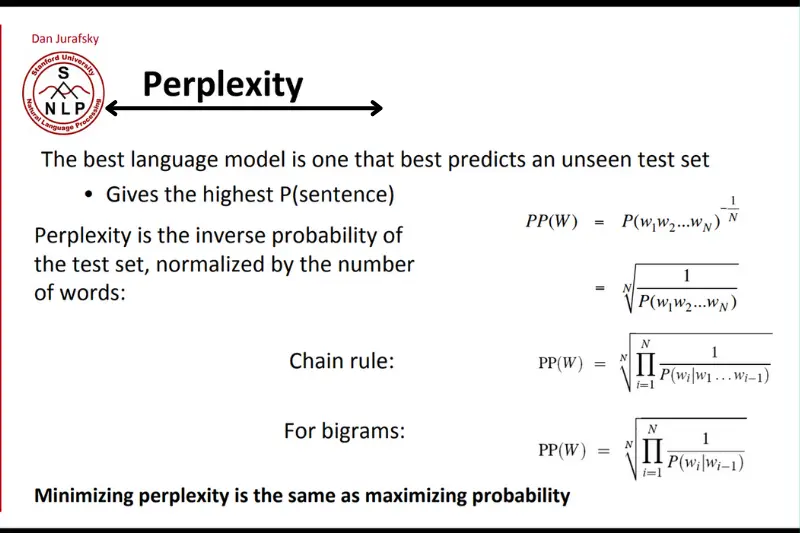
Mathematically, perplexity is defined as the exponentiation of the cross-entropy of the model. For a language model, it is expressed as:
Perplexity = 2−1/N∑i=1Nlog2(P(xi))
Here:
- NNN is the total number of tokens (e.g., words or characters) in the dataset.
- P(xi)P(x_i)P(xi) is the probability assigned by the model to the iii-th token.
This formula essentially calculates the average uncertainty of the model when predicting tokens in a dataset.
You May Also Like it:
10+ Free Online Typing Jobs Without Any Investment [2025]
Top 10 Direct Selling Companies In India [2025] – Kongo Tech
10+ Best Indian Captcha Entry Work Without Investment In 2025
Perplexity in Intuitive Terms
Perplexity, in the context of language models, is a way to measure how well a model predicts the next word or item in a sequence. You can think of perplexity as a gauge of a model’s uncertainty or “confusion” when making predictions. It reflects how many plausible choices the model considers at each step of prediction.
- Perplexity of 1: Indicates that the model is entirely confident in its predictions. It assigns a probability of 1 to the correct choice, meaning it is certain about the next word or outcome.
- Perplexity of 10: Implies that, on average, the model considers 10 equally likely options. This higher number indicates greater uncertainty.
The lower the perplexity score, the better the model performs. A low perplexity means the model is less perplexed by the input data and can predict the next word or sequence more accurately.
Example to Illustrate Perplexity
Imagine the sentence:
“I like to eat ____.”
- Low Perplexity Scenario:
If the model predicts “apple” with a probability of 0.9, it shows high confidence and understanding of the context. This results in a low perplexity score. - High Perplexity Scenario:
If the model assigns equal probabilities (e.g., 0.25 each) to “apple,” “orange,” “grape,” and “banana,” it indicates uncertainty in its prediction, leading to a higher perplexity score.
How Perplexity Works
In practice, perplexity serves as a diagnostic tool to evaluate how well a language model predicts a sequence of text. It is particularly useful for understanding whether a model has learned the structure and context of language or is simply making random guesses.
Example of Perplexity in Action
Consider a scenario where a language model is tasked with predicting the next word in the sentence:
“The cat sat on the ____.”
- Low Perplexity Scenario:
- If the model predicts “mat” with a probability of 0.9, it demonstrates strong contextual understanding, resulting in a low perplexity score.
- This indicates the model has effectively learned the relationship between the words in the sentence and the likely continuation.
- High Perplexity Scenario:
- If the model assigns probabilities of 0.25 each to “mat,” “table,” “floor,” and “chair,” it suggests that the model is unsure about the correct prediction.
- The higher perplexity score reflects the model’s uncertainty and lack of confidence in the context.
By analyzing perplexity scores, researchers can determine whether a language model is improving during training and whether it can generalize well to new data.
Applications of Perplexity
Perplexity has numerous applications in natural language processing, making it a critical metric in evaluating and developing language models.
1. Evaluating Language Models
Perplexity is a widely used metric for assessing the performance of various types of language models, including:
- Traditional n-gram models.
- Modern deep learning-based models like GPT, BERT, and LLaMA.
A lower perplexity score signifies better performance, indicating that the model can predict text with greater confidence and accuracy.
Example:
- Model A has a perplexity score of 20.
- Model B has a perplexity score of 50.
Model A is considered superior because it demonstrates a better understanding of the language structure.
2. Guiding Model Training
Perplexity is often monitored during the training of language models to evaluate progress and effectiveness.
- A steady decrease in perplexity over epochs (iterations of training) indicates that the model is learning and improving.
- If perplexity plateaus or increases, it may suggest issues such as overfitting or insufficient training data.
By observing perplexity trends, developers can adjust hyperparameters or modify training strategies to improve model performance.
3. Benchmarking Models
Perplexity serves as a reliable benchmark for comparing different models or configurations on the same dataset.
Use Case:
- Researchers train multiple models with varying architectures or hyperparameters.
- The model with the lowest perplexity on a validation dataset is often selected as the most effective.
This process ensures that the chosen model performs well in terms of predicting language while maintaining computational efficiency.
4. Applications in NLP Tasks
Perplexity plays a crucial role in evaluating and enhancing NLP tasks, such as:
- Speech Recognition:
- In automatic speech recognition (ASR) systems, perplexity is used to measure how well a model can transcribe spoken words into text.
- A lower perplexity score indicates that the system is more accurate in predicting the correct transcription.
- Machine Translation:
- Perplexity is an important metric for assessing machine translation models.
- Lower perplexity suggests better alignment with the grammar, syntax, and vocabulary of the target language, resulting in more accurate translations.
- Text Generation:
- Models like GPT are evaluated using perplexity to ensure that they generate fluent, coherent, and contextually relevant text.
- Lower perplexity in text generation models indicates their ability to produce high-quality outputs that mimic human language.
Examples of Perplexity in Action
Let’s explore perplexity with the help of two hypothetical language models, Model A and Model B, tasked with predicting the next word in a sentence.
Scenario: Predicting the Next Word
Suppose the context is:
“I like to eat ____.”
The correct next word is “apple.”
Model A assigns the following probabilities to the potential next words:
- “apple”: 0.8
- “banana”: 0.1
- “orange”: 0.05
- “grape”: 0.05
Model B, in contrast, assigns equal probabilities to all options:
- “apple”: 0.25
- “banana”: 0.25
- “orange”: 0.25
- “grape”: 0.25
Analysis of Perplexity Scores
- Model A:
- Here, the model is highly confident that “apple” is the correct word, assigning it a probability of 0.8.
- Since the probability distribution is skewed heavily toward the correct choice, Model A’s perplexity will be lower, reflecting better performance.
- Model B:
- Model B assigns equal probabilities to all words, indicating it is uncertain about the correct prediction.
- This uniform distribution leads to a higher perplexity score, showing that the model is less confident and performs worse.
Key Insight:
Lower perplexity scores indicate that a model is better at predicting the correct next word, while higher scores suggest greater uncertainty or confusion.
You may also like it:
AV Tub – Detailed Guide – Unveiling The World Of Music
Trendzguruji.me Cyber – Complete Guide – Detailed Overview
Croxyproxy Youtube Unblocked [2025] – Watch YT Blocked Videos
Benefits of Using Perplexity
Perplexity is a fundamental metric in evaluating language models, offering several advantages that make it valuable for researchers and developers. Below are the benefits of using perplexity:
1. Quantifiable Measure
Perplexity provides a concrete numerical value indicating a model’s predictions’ confidence. This value helps quantify the model’s performance, enabling objective evaluation without relying on subjective interpretation.
- Why It’s Useful:
Perplexity offers a clear, measurable way to determine how well a model predicts text, making it easier to compare and benchmark models. - Example:
A model with a perplexity score of 10 performs better than one with a score of 50 because it is less “perplexed” and more confident in predicting the next word or sequence. The numerical nature of perplexity eliminates ambiguity and provides a standardized evaluation metric.
2. Effective Comparison
Perplexity allows researchers to objectively compare the performance of different models or configurations on the same dataset. By calculating perplexity scores, it becomes possible to identify the best-performing model for a specific task.
- How It Helps:
Comparative analysis is crucial in selecting the most effective model during development. Perplexity acts as a reliable benchmark for making informed decisions. - Example:
Suppose two models are tested on the same dataset:- Model X: Perplexity = 15
- Model Y: Perplexity = 30
Here, Model X is preferred because its lower perplexity score reflects better text prediction capabilities.
3. Insight into Learning
Monitoring perplexity during training provides valuable insights into a model’s learning process. A steady decline in perplexity over time indicates that the model is improving and becoming more confident in its predictions.
- Use Case:
During training, developers observe perplexity trends to identify potential issues:- Steady Decrease: The model is learning effectively.
- Plateau or Increase: Indicates problems such as overfitting, insufficient training data, or improper hyperparameter tuning.
- How It Guides Optimization:
If perplexity plateaus, developers can adjust the training process, such as refining the dataset, tweaking hyperparameters, or using regularization techniques to improve the model’s performance and generalization capabilities.
Limitations of Perplexity
Despite its advantages, perplexity has several limitations that affect its reliability and interpretation. Understanding these limitations is essential to avoid misusing the metric.
1. Dataset Dependency
Perplexity scores are calculated based on a specific dataset, meaning their values depend heavily on the dataset’s structure, vocabulary, and complexity. This dependency can make it challenging to compare perplexity scores across different datasets.
- Why It’s a Problem:
A model trained on a simpler dataset might show lower perplexity, but that doesn’t necessarily mean it’s better. The complexity of the dataset plays a significant role in determining perplexity scores. - Example:
- Model A, trained on a straightforward dataset, achieves a perplexity of 12.
- Model B, trained on a complex dataset, has a perplexity of 25.
While Model A appears better based on perplexity, Model B might be more robust and capable of handling real-world data.
2. Lack of Alignment with Human Judgment
Perplexity measures statistical confidence in predictions but does not always align with human notions of fluency, coherence, or relevance in text.
- Why It’s a Concern:
A model with low perplexity might generate text that is grammatically correct but awkward, unnatural, or irrelevant to the context. - Example:
A model might generate the sentence:
“The sky is green”
This prediction might have a low perplexity score due to high statistical confidence, but it is factually incorrect and does not align with human understanding.
3. Sensitivity to Vocabulary Size
The size of a model’s vocabulary can significantly impact its perplexity scores.
- Small Vocabulary:
Models with smaller vocabularies might achieve artificially low perplexity because their limited range of possible outputs simplifies predictions. - Large Vocabulary:
Models with extensive vocabularies face higher uncertainty in predictions, potentially leading to higher perplexity scores, even if they better capture linguistic nuances. - Why It Matters:
Comparing perplexity scores between models with vastly different vocabulary sizes can be misleading. Vocabulary size must be considered when interpreting perplexity results.
4. Overfitting Risks
A model trained extensively on a specific dataset might achieve very low perplexity by memorizing the dataset’s patterns and sequences. However, such overfitting compromises the model’s ability to generalize to unseen data.
- How It Affects Performance:
Overfitting gives a false sense of confidence in the model’s ability to predict text. While the perplexity on the training dataset is low, the model might struggle with new, real-world data. - Example:
A model achieves low perplexity on training data but performs poorly on validation or test datasets. This indicates that the model has memorized the training data rather than learning the underlying patterns of the language.
Alternatives to Perplexity
Given its limitations, perplexity is often complemented by other evaluation metrics that provide a more comprehensive assessment of a language model’s performance.
1. BLEU (Bilingual Evaluation Understudy)
- Commonly used in machine translation tasks.
- Measures the overlap between generated translations and reference translations using n-grams.
- Provides a score indicating how well the generated text matches human-provided translations.
2. ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
- Frequently applied in text summarization.
- Compares the overlap of words, phrases, or sequences between the generated summary and a reference summary.
- Useful for evaluating the relevance and completeness of generated content.
3. Human Evaluation
- Involves direct assessment by humans to gauge fluency, coherence, and relevance of generated text.
- Provides qualitative insights that automated metrics cannot capture, such as emotional tone or logical consistency.
- Often considered the most reliable method despite being time-consuming and resource-intensive.
Conclusion
Perplexity is a fundamental metric in evaluating probabilistic language models, offering insights into their ability to predict sequences and handle the complexities of natural language.
Its mathematical foundation provides a quantifiable measure of model uncertainty, making it indispensable for assessing performance, guiding training, and benchmarking models across various NLP tasks.
However, perplexity is not without its limitations. Its dependency on dataset complexity, sensitivity to vocabulary size, and misalignment with human judgment highlight the need for complementary evaluation methods. Metrics like BLEU, ROUGE, and human evaluation help fill these gaps, ensuring a more holistic understanding of model performance.
In the evolving field of NLP, perplexity remains a cornerstone metric, but its use must be contextualized within broader evaluation frameworks to develop robust and reliable language models capable of meeting real-world challenges.
FAQs
1. What is perplexity in natural language processing (NLP)?
Perplexity is a metric used to evaluate how well a probabilistic model, particularly a language model, predicts a sequence of words or tokens. It measures the model’s uncertainty when predicting the next word in a sequence. A lower perplexity score indicates that the model is more confident and accurate in its predictions.
2. How is perplexity calculated?
Perplexity is calculated using the following formula:
Perplexity=2−1N∑i=1Nlog2(P(xi))
Where:
NNN is the total number of tokens (e.g., words or characters) in the dataset.
P(xi)P(x_i)P(xi) is the probability assigned by the model to the iii-th token.
This formula essentially calculates the average uncertainty in predicting tokens, with lower values indicating better model performance.
3. What does a low perplexity score mean?
A low perplexity score indicates that the model is confident and accurate in predicting the next word or sequence in a given context. It shows that the model has learned the patterns and relationships in the data and can make reliable predictions.
4. What does a high perplexity score mean?
A high perplexity score suggests that the model is uncertain about its predictions and is considering multiple possible options for the next word or sequence. It may indicate that the model has not learned the context well or is unable to predict accurately.
5. Why is perplexity important in NLP?
Perplexity helps in evaluating the effectiveness of language models, guiding model training, and benchmarking different models. It provides a quantifiable measure of how well a model can predict text, making it easier to compare the performance of different models or configurations.
6. Can perplexity be used to compare different datasets?
Not always. Perplexity scores are highly dependent on the dataset, meaning they may not be directly comparable across different datasets. A model trained on a simpler dataset might show lower perplexity, but this doesn’t necessarily indicate better performance compared to a model trained on a more complex dataset.
You May Also Like This
How To Earn Money From Instagram Reels In 2025? – Make Money Online
How To Increase Organic Reach On Instagram – Boost Your Online Presence
How To Monetize Instagram Account In 2025– Earn Money From Insta
Aman Dhattarwal Net Worth, Income, And Expenses Report – Kongo Tech
Theapknews.shop Health & Beauty – Detailed Guide – Kongo Tech
Healthy Life Wellhealthorganic – Complete Guide – Kongo Tech
Wellhealthorganic Home Remedies Tag – Complete Guide – Kongo Tech